A OpenAI lançou dois novos modelos de idiomas de peso aberto sob a licença permissiva do Apache 2.0. Esses modelos foram projetados para oferecer um forte desempenho no mundo real enquanto executam hardware de consumo, incluindo um modelo que pode ser executado em um laptop de ponta com apenas 16 GB de GPU.
Desempenho do mundo real a menor custo de hardware
Os dois modelos são:
- GPT-OSS-120B (117 bilhões de parâmetros)
- GPT-OSS-20B (21 bilhões de parâmetros)
O modelo GPT-OSS-120B maior corresponde ao O4-Mini do OpenAI nos benchmarks de raciocínio, exigindo apenas uma única GPU de 80 GB. O modelo menor GPT-20B tem um desempenho semelhante ao O3-mini e é executado com eficiência em dispositivos com apenas 16 GB de GPU. Isso permite que os desenvolvedores executem os modelos em máquinas de consumo, facilitando a implantação sem infraestrutura cara.
Raciocínio avançado, uso de ferramentas e cadeia de pensamento
Openai explica O fato de os modelos superar outros modelos de código aberto de tamanhos semelhantes nas tarefas de raciocínio e no uso de ferramentas.
De acordo com o Openai:
“Esses modelos são compatíveis com nossas respostas API (abre em uma nova janela) e são projetados para serem usados em fluxos de trabalho agênticos com instrução excepcional a seguir, o uso da ferramenta, como pesquisa na web ou execução de código Python e recursos de raciocínio-incluindo a capacidade de retenção e a capacidade de raciocínio e/ou/ou com alvo de baixa latência. Saídas estruturadas (abre em uma nova janela). ”
Projetado para flexibilidade e integração do desenvolvedor
Openai lançou guias de desenvolvedor Para apoiar a integração com plataformas como Abraçando o rostoAssim, Githubvllm, ollama e llama.cpp. Os modelos são compatíveis com a API de respostas do OpenAI e os comportamentos avançados de acompanhamento de instruções e raciocínio. Os desenvolvedores podem ajustar os modelos e implementar a segurança de segurança para aplicativos personalizados.
Segurança em modelos de IA de peso aberto
O Openai abordou seus modelos de peso aberto com o objetivo de garantir a segurança durante todo o treinamento e o lançamento. Os testes confirmaram que, mesmo sob ajuste fino propositalmente malicioso, o GPT-OSS-120B não atingiu um nível perigoso de capacidade em áreas de risco biológico, químico ou cibernético.
Cadeia de pensamento não filtrada
O OpenAI está intencionalmente deixando a cadeia de pensamento (COTS) não filtrada durante o treinamento para preservar sua utilidade para o monitoramento, com base na preocupação de que a otimização possa fazer com que os modelos ocultem seu raciocínio real. Isso, no entanto, pode resultar em alucinações.
De acordo com o cartão de modelo (Versão em PDF):
“Em nossa pesquisa recente, descobrimos que o monitoramento da cadeia de pensamento de um modelo de raciocínio pode ser útil para detectar o mau comportamento. Descobrimos ainda que os modelos podem aprender a esconder seu pensamento enquanto ainda se comporta se seus berços fossem diretamente pressionados contra ter ‘pensamentos ruins’.
Mais recentemente, ingressamos em um documento de posição com vários outros laboratórios argumentando que os desenvolvedores de fronteira devem ‘considerar o impacto das decisões de desenvolvimento na monitorabilidade da berços’.
De acordo com essas preocupações, decidimos não colocar nenhuma pressão de otimização direta no COT para nenhum dos dois modelos de peso aberto. Esperamos que isso ofereça aos desenvolvedores a oportunidade de implementar sistemas de monitoramento de COT em seus projetos e permite que a comunidade de pesquisa estude ainda mais a monitorabilidade da BCT. ”
Impacto nas alucinações
A documentação do Openai afirma que a decisão de não restringir a cadeia de pensamento resulta em maiores escores de alucinação.
A versão em PDF do cartão modelo explica por que isso acontece:
Como essas cadeias de pensamento não são restritas, elas podem conter conteúdo alucinado, incluindo linguagem que não reflete as políticas de segurança padrão do OpenAI. Os desenvolvedores não devem mostrar diretamente cadeias de pensamento para os usuários de seus aplicativos, sem filtragem, moderação ou resumo desse tipo de conteúdo. ”
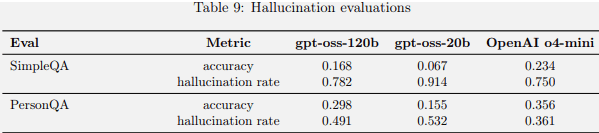
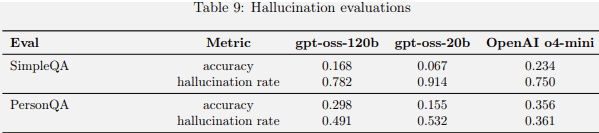
O benchmarking mostrou que os dois modelos de código aberto tiveram um desempenho menos bom nos benchmarks de alucinação em comparação com o Openai O4-mini. A documentação do PDF do cartão do modelo explicou que isso era de se esperar porque os novos modelos são menores e implica que os modelos alucinarão menos em configurações agênticas ou ao procurar informações na Web (como RAG) ou extraí -lo de um banco de dados.
Pontuações de benchmarking de alucinação OPENAI OSS
Takeaways
- Liberação de peso aberto
O OpenAI lançou dois modelos de peso aberto sob a licença permissiva do Apache 2.0. - Performance vs. Custo de hardware
Os modelos oferecem um forte desempenho de raciocínio ao executar em hardware acessível do mundo real, tornando-os amplamente acessíveis. - Modelo Especificações e Capacidades
O GPT-OSS-120B corresponde a O4-mini no raciocínio e funciona na GPU de 80 GB; O GPT-OSS-20B tem um desempenho semelhante ao O3-Mini em benchmarks de raciocínio e é executado com eficiência na GPU de 16 GB. - Fluxo de trabalho agêntico
Ambos os modelos suportam saídas estruturadas, uso de ferramentas (como Python e pesquisa na Web) e podem escalar seu esforço de raciocínio com base na complexidade da tarefa. - Personalização e integração
Os modelos são construídos para se encaixar em fluxos de trabalho agênticos e podem ser totalmente adaptados a casos de uso específicos. Seu suporte a saídas estruturadas os torna adaptáveis a sistemas de software complexos. - Uso da ferramenta e chamada de função
Os modelos podem executar chamadas de função e uso de ferramentas com poucos impulsionamentos, tornando-os eficazes para tarefas de automação que exigem raciocínio e adaptabilidade. - Colaboração com usuários do mundo real
O OpenAI colaborou com parceiros como AI Suécia, Orange e Snowflake para explorar os usos práticos dos modelos, incluindo implantação segura no local e ajuste fino personalizado em conjuntos de dados especializados. - Otimização de inferência
Os modelos usam a mistura de especialistas (MOE) para reduzir a carga de computação e a atenção multi-quadra agrupada para inferência e eficiência da memória, facilitando a execução a um custo menor. - Segurança
Os modelos de código aberto do OpenAI mantêm a segurança mesmo sob ajuste malicioso; A cadeia de pensamentos (COTs) não é filtrada para transparência e monitorabilidade. - Troca de transparência do berço
Nenhuma pressão de otimização aplicada aos COTs para evitar o mascaramento do raciocínio prejudicial; pode resultar em alucinações. - Alucinações referências e desempenho do mundo real
Os modelos têm um desempenho abaixo do O4-mini nos benchmarks de alucinação, que abre os atributos ao seu tamanho menor. No entanto, em aplicativos do mundo real, onde os modelos podem procurar informações da web ou de consultas de conjuntos de dados externos, espera-se que as alucinações sejam menos frequentes.
Imagem em destaque de Shutterstock/Good Dreams – Studio
#Por #modelos #código #aberto #OpenAI #são #grande #negócio