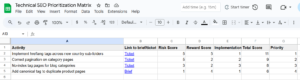
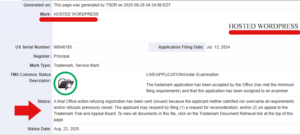
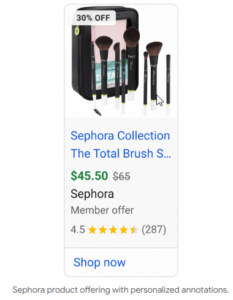
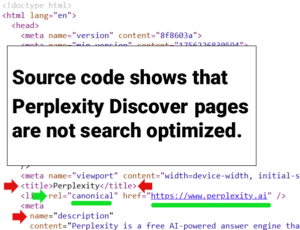
Hoje, os profissionais de marketing gastam seu tempo em pesquisas de palavras -chave para descobrir oportunidades, fechando lacunas de conteúdo, garantindo que as páginas sejam rastreadas e alinhando o conteúdo com os princípios do EEAT. Essas coisas ainda importam. Mas em um mundo em que a IA generativa medeia cada vez mais informações, elas não são suficientes.
A diferença agora é recuperação. Não importa o quão polido ou autoritário seja seu conteúdo para um humano se a máquina nunca o puxa para o conjunto de respostas. A recuperação não é apenas se sua página existe ou se é tecnicamente otimizada. É sobre como as máquinas interpretam o significado dentro de suas palavras.
Isso nos leva a dois fatores que a maioria das pessoas não pensa muito, mas que está rapidamente se tornando essencial: densidade semântica e sobreposição semântica. Eles estão intimamente relacionados, muitas vezes confusos, mas, na prática, geram resultados muito diferentes na recuperação de Genai. Compreendê -los e aprender a equilibrá -los pode ajudar a moldar o futuro da otimização do conteúdo. Pense neles como parte da nova camada de otimização na página.
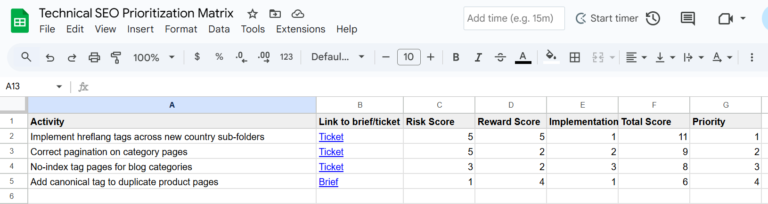
 Crédito da imagem :: Duane Forrester
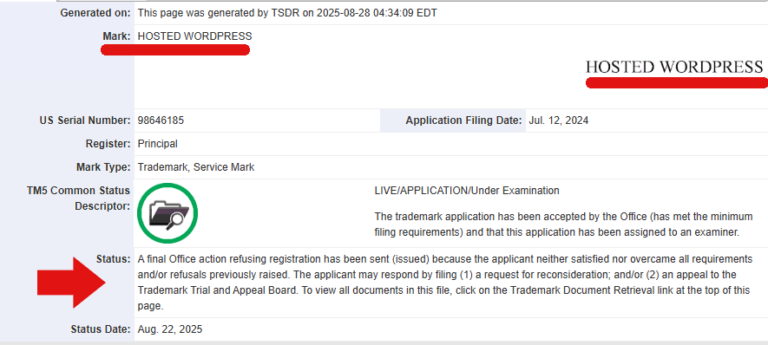
Crédito da imagem :: Duane ForresterDensidade semântica é sobre significado por token. Um denso bloco de texto comunica informações máximas com o menor número de palavras possíveis. Pense em uma definição nítida em um glossário ou em um resumo executivo bem escrito. Os seres humanos tendem a gostar de conteúdo denso porque sinaliza autoridade, economiza tempo e parece eficiente.
Sobreposição semântica é diferente. A sobreposição mede o quão bem seu conteúdo está alinhado com a representação latente de uma consulta de um modelo. Os motores de recuperação não lêem como humanos. Eles codificam significado em vetores e comparam semelhanças. Se o seu pedaço de conteúdo compartilhar muitos dos mesmos sinais que a consulta incorporando, ele será recuperado. Caso contrário, permanece invisível, por mais elegante que seja a prosa.
Esse conceito já está formalizado na avaliação do processamento de linguagem natural (PNL). Uma das medidas mais amplamente usadas é Bertscore (https://arxiv.org/abs/1904.09675), introduzido por pesquisadores em 2020. Compara as incorporações de dois textos, como uma consulta e uma resposta, e produz uma pontuação de similaridade que reflete a sobreposição semântica. O BertScore não é uma ferramenta do Google SEO. É uma métrica de código aberto enraizada na família Bert Model, originalmente desenvolvida pelo Google Research, e tornou-se uma maneira padrão de avaliar o alinhamento no processamento de linguagem natural.
Agora, aqui é onde as coisas se separaram. Os seres humanos recompensam a densidade. Máquinas recompensam a sobreposição. Uma frase densa pode ser admirada pelos leitores, mas ignorada pela máquina se não se sobrepor ao vetor de consulta. Uma passagem mais longa que repete os sinônimos, reformula perguntas e as entidades relacionadas às superfícies pode parecer redundante para as pessoas, mas se alinha mais fortemente com a recuperação da consulta e das vitórias.
Na era das palavras -chave do SEO, a densidade e a sobreposição foram embaçadas juntas sob práticas de otimização. Escrever naturalmente, incluindo variações suficientes de uma palavra -chave frequentemente alcançada. Na recuperação de Genai, os dois divergem. Otimizar para um não garante o outro.
Essa distinção é reconhecida nas estruturas de avaliação já usadas no aprendizado de máquina. Bertscore, por exemplo, mostra que uma pontuação mais alta significa maior alinhamento com o significado pretendido. Isso se sobrepõe importa muito mais para a recuperação do que a densidade sozinha. E se você realmente deseja mergulhar profundamente nas métricas de avaliação de LLM, este artigo é um ótimo recurso.
Os sistemas generativos não ingerem e recuperam páginas da web inteiras. Eles trabalham com pedaços. Modelos de idiomas grandes são combinados com bancos de dados vetoriais em sistemas de geração de recuperação de recuperação (RAG). Quando uma consulta entra, ela é convertida em incorporação. Essa incorporação é comparada com uma biblioteca de incorporações de conteúdo. O sistema não pergunta “Qual é a página mais bem escrita?” Ele pergunta “Quais pedaços vivem mais perto desta consulta no espaço vetorial?”
É por isso que a sobreposição semântica é importante mais que a densidade. A camada de recuperação é cega para a elegância. Prioriza o alinhamento e a coerência por meio de escores de similaridade.
Tamanho e estrutura do pedaço Adicione a complexidade. Muito pequeno, e um pedaço denso pode perder sinais de sobreposição e ser passado. Muito grande, e um pedaço detalhado pode ser bem classificado, mas frustrar os usuários com o Bloat, uma vez que surgir. A arte é equilibrar o significado compacto com pistas de sobreposição, estruturando pedaços para que eles sejam alinhados semanticamente e fáceis de ler uma vez recuperados. Os profissionais geralmente testam tamanhos de parceria entre 200 e 500 tokens e 800 e 1.000 tokens para encontrar o equilíbrio que se encaixa em seus padrões de domínio e consulta.
A Microsoft Research oferece um exemplo impressionante. Em um estudo de 2025 analisando 200.000 conversas anônimas no Bing Copilot, os pesquisadores descobriram que as tarefas de coleta e redação de informações obtiveram maior pontuação no sucesso da recuperação e na satisfação do usuário. O sucesso da recuperação não rastreia com a compactação da resposta; Ele rastreou com sobreposição entre o entendimento do modelo sobre a consulta e o fraseado usado na resposta. De fato, em 40% das conversas, a sobreposição entre a meta do usuário e a ação da IA foi assimétrica. A recuperação aconteceu onde a sobreposição era alta, mesmo quando a densidade não era. Estudo completo aqui.
Isso reflete uma verdade estrutural dos sistemas de recuperação. Sobreposição, não brevidade, é o que você o coloca no conjunto de respostas. O texto denso sem alinhamento é invisível. O texto verboso com alinhamento pode surgir. O motor de recuperação se preocupa mais com a incorporação de similaridade.
Isso não é apenas teoria. Os profissionais de pesquisa semântica já medem a qualidade por meio de métricas de alinhamento de intenção, em vez da frequência de palavras-chave. Por exemplo, o Milvus, um banco de dados vetorial de código aberto líder, destaca as métricas baseadas em sobreposições como a maneira correta de avaliar o desempenho da pesquisa semântica. Seu guia de referência Enfatiza o significado semântico correspondente sobre as formas de superfície.
A lição é clara. Máquinas não o recompensam por elegância. Eles o recompensam pelo alinhamento.
Há também uma mudança na maneira como pensamos sobre a estrutura necessária aqui. A maioria das pessoas vê pontos de bala como abreviação; fragmentos rápidos e digitalizáveis. Isso funciona para os seres humanos, mas as máquinas as leem de maneira diferente. Para um sistema de recuperação, uma bala é um sinal estrutural que define um pedaço. O que importa é a sobreposição dentro desse pedaço. Uma bala curta e despojada pode parecer limpa, mas carrega pouco alinhamento. Uma bala mais longa e rica, que repete as entidades -chave, inclui sinônimos e frases de idéias de várias maneiras, tem uma chance maior de recuperação. Na prática, isso significa que as balas podem precisar ser mais cheias e mais detalhadas do que estamos acostumados a escrever. A brevidade não o leva ao conjunto de respostas. Sobreposição faz.
Se a recuperação de unidades de sobreposição, isso significa que a densidade não importa? De jeito nenhum.
A sobreposição leva você a recuperar. A densidade mantém você credível. Uma vez que seu pedaço está surgido, um humano ainda precisa lê -lo. Se esse leitor o achar inchado, repetitivo ou desleixado, sua autoridade se erodia. A máquina decide visibilidade. O humano decide confiança.
O que está faltando hoje é uma métrica composta que equilibra os dois. Podemos imaginar duas pontuações:
Pontuação de densidade semântica: Isso mede o significado por token, avaliando a eficiência da informação transmitida. Isso pode ser aproximado por taxas de compressão, fórmulas de legibilidade ou mesmo pontuação humana.
Pontuação de sobreposição semântica: Isso mede o quão fortemente um pedaço se alinha com uma consulta incorporada. Isso já é aproximado por ferramentas como Bertscore ou similaridade de cosseno no espaço vetorial.
Juntos, essas duas medidas nos dão uma imagem mais completa. Uma parte do conteúdo com uma pontuação de alta densidade, mas a baixa sobreposição lê lindamente, mas pode nunca ser recuperada. Uma peça com uma alta pontuação de sobreposição, mas a baixa densidade pode ser recuperada constantemente, mas frustra os leitores. A estratégia vencedora está buscando ambos.
Imagine duas passagens curtas respondendo à mesma consulta:
Versão densa: “Os sistemas de trapos recuperam pedaços de dados relevantes para uma consulta e os alimentam a um LLM.”
Versão de sobreposição: “A geração de recuperação, geralmente chamada RAG, recupera pedaços de conteúdo relevantes, compara suas incorporações à consulta do usuário e passa os pedaços alinhados a um grande modelo de linguagem para gerar uma resposta.”
Ambos estão factualmente corretos. O primeiro é compacto e claro. O segundo é Wordier, repete as principais entidades e usa sinônimos. A versão densa pontua mais com os seres humanos. A versão de sobreposição pontua mais com as máquinas. Qual é recuperado com mais frequência? A versão de sobreposição. Qual deles ganha confiança uma vez recuperado? O denso.
Vamos considerar um exemplo não técnico.
Versão densa: “A vitamina D regula a saúde do cálcio e dos ossos.”
Versão rica em sobreposição: “A vitamina D, também chamada Calciferol, suporta absorção de cálcio, crescimento ósseo e densidade óssea, ajudando a prevenir condições como osteoporose”.
Ambos estão corretos. O segundo inclui sinônimos e conceitos relacionados, que aumentam a sobreposição e a probabilidade de recuperação.
É por isso que o futuro da otimização não está escolhendo densidade ou sobreposição, está equilibrando os dois
Assim como os primeiros dias do SEO viram métricas como densidade de palavras -chave e backlinks evoluir para medidas de autoridade mais sofisticadas, a próxima onda formalizará a densidade e sobrepõe as pontuações em painéis de otimização padrão. Por enquanto, continua sendo um ato de equilíbrio. Se você escolher sobreposição, é provável que seja uma aposta segura, pois pelo menos você recupera. Então, você deve esperar que as pessoas que lêem seu conteúdo como resposta achem que é envolvente o suficiente para permanecer.
A máquina decide se você é visível. O humano decide se você é confiável. A densidade semântica afia o significado. A sobreposição semântica vence a recuperação. O trabalho está equilibrando os dois e, em seguida, observando como os leitores se envolvem, para que você possa continuar melhorando.
Mais recursos:
Este post foi publicado originalmente em Duane Forrester decodifica.
Imagem em destaque: CaptainMCity/Shutterstock
#Encontrando #equilíbrio #ganha #recuperação